
Die Erzeugung von LoRAs ist prinzipiell zwar nicht ganz trivial, dank einiger gut durchdachter Tools aber recht einfach durchzuführen. Wie bei den großen Modellen aber auch, so ist es hier wichtig gutes und ausreichendes Lernmaterial zu haben.
Es zeigt sich schnell dass damit Stile recht gut übernommen werden können, dabei aber oftmals die Realitätsnähe, die flux.dev bereits bei realen Personen erreicht, durch den Cartoon LoRA-Stil wieder verloren geht.
Es können wieder erneut viele Fehler, wie doppelte Arme oder das durchdringen von Gegenständen, auftreten.

Um selber eine LoRA zu erzeugen benötigt man ein entsprechendes Tool, Lernmaterial und Zeit. Auch mit einer guten Grafikkarte kann die Laufzeit einige Stunden betragen.
Wir haben fluxgym unter pinokio genutzt. Die Details und Einzelparameter können wir hier nicht beschreiben, aber unserer Erfahrung nach funktionieren die Defaultwerte gut. Man muss auswählen wie viel Speicher man hat und für welches Modell man eine LoRA erzeugen will.
Dann lädt man einfach das Lernmaterial in Form einzelner Bilder hoch, beschreibt diese, vergibt einen Dateinamen, sowie ein Trigger Wort, und kann danach den Erzeugungslauf starten.
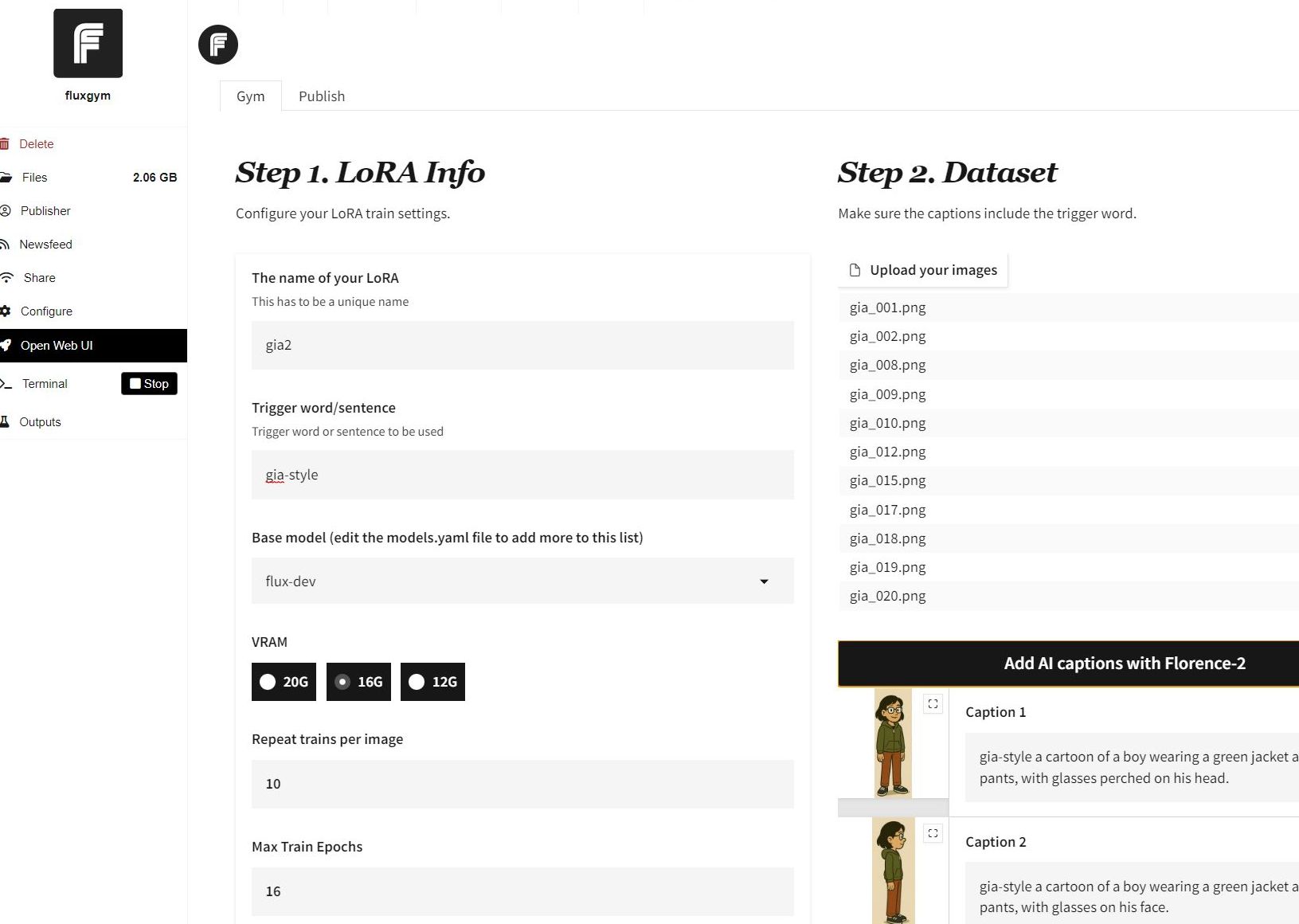
Die Beschreibungen für die zu lernenden Bilder kann auch das Programm selber machen, einfach durch Aufrufen des Florence-2 Modells von Microsoft zur Bildbeschreibung. Allerdings enthalten diese meist immer einige Fehler (Im Screenshot z.B. boy statt girl oder young woman). Dieses lassen sich aber leicht korrigieren.
Anmerkung: Andere sind nach Tests zu der Erkenntnis gelangt, daß man die Beschreibungen besser leer lässt. Wenn nämlich etwas in der Beschreibung steht wird auch nur das wirklich mitgelernt, was auch genau beschrieben wurde.
Anders ausgedrückt. was nicht drin steht kommt auch nicht rein.
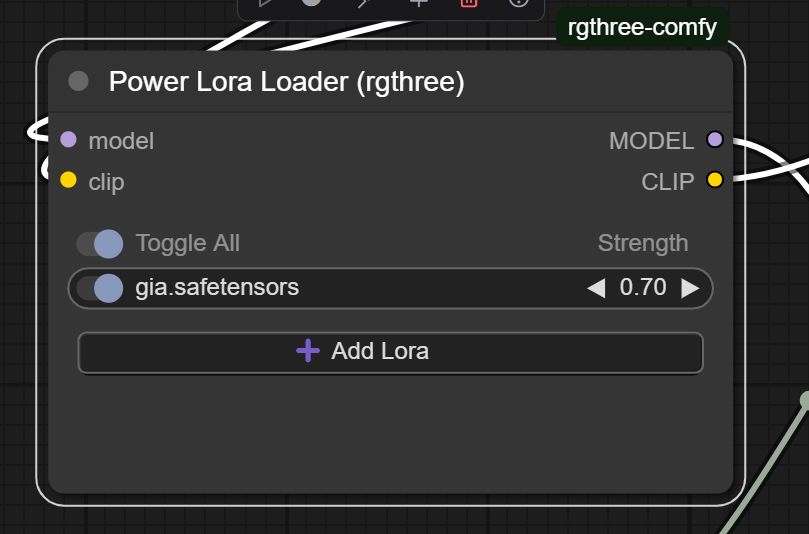
Wenn alles geklappt hat und man keinen Memoryüberlauf o.ä. anderes unschönes hat, erhält man dann nach einigen Stunden eine .safetensors Datei die man in das entsprechende Verzeichnis in ComfyUI kopieren und dann nach einem refresh der Oberfläche selektieren und nutzen kann.
A cinematic view of a young woman gia-style with a green sweatshirt, halflong black hair, white sneakers and glasses. She is in her nicely decorated living room. She is sitting at a desk behind a computer screen and a keyboard. She is looking at the computer screen and has a look of surprise on her face and in her gesture. On her computer screen there is a bald man in a blue business suit raising his hand, cautioning awareness, warning the viewer about something important. There is a portrait of a woman on the wall. There is a cute little dog at her feet looking up to her.

Es wird nicht immer alles aus dem prompt übernommen. Das liegt zum einen am Prompt selber. Er muss möglichst genau sein und darf keine impliziten Anordnungen beinhalten, wie sie Menschen verstehen würden. Zudem braucht es Konsistenz und der K.I. muss auch in der Lage sein all die Elemente zu kombinieren.
Entscheidend hierbei sind aber auch 2 Parameter in den Ablaufmodulen. Zu einem die ‚LoRA Strength‘, bei diesem Beispiel auf 0.7 gesetzt. Dieser gibt den Einfluss der LoRA an. Das muss man immer wieder nachjustieren und ausprobieren. Bei mehreren LoRAs sollten alle insgesamt nicht mehr als 1.0 haben.
Der zweite Parameter ist der ‚guidance level‘ im FluxGuidance Knoten. ForestLabs empfiehlt hier 2.5 für flux.dev. Er gibt an wie kreativ die K.I. sein soll.
Niedrige Werte = Mehr kreativ.
Höhere Werte (mehr als 20.0 sollte es nicht sein) = Mehr dem prompt folgen.
In unserem Beispiel war der Wert 4.0. Auch hier muss man immer wieder nachjustieren und ausprobieren.
Also der Hund war zufrieden. 